On this page I present a robust, custom build system for a software project written in C, in less than 500 lines of Python code. I think it is about as minimal as a practical dependency-tracking build system can get. Although it adds to the code that must be maintained as part of the project, I think that having a custom build infrastructure that can grow with the project is a good idea for medium-sized and larger projects.
I've been working on a software project that has a build of non-trivial complexity. And I'm fed up with unintelligible, unflexible build systems. Possibly still the most widely used build system, Make, is a good one. It gets the basics right. But it has well known deficiencies -- its configuration syntax is awkward, and it is restricted to filesystem files and shell commands. I've also used CMake for a while, and although I feel it must have a robust underlying model, I don't really know what the model is, and I don't think there is a officially sanctioned interface to program the model directly. Nobody I know seems to really understand how CMake's scripting language works. It is focused on providing high-level abstractions and pre-made solutions with lots of black magic. The documentation does not have the best reputation, and 100 kloc of C++ code? Not for me.
One thing I expect from a build system is that it lets me easily create a build description by transforming from my own data structures (e.g. in a schema / language of my own choice), so that I can be absolutely clear about the semantics. It's also nice to be able to use that data for other purposes, to try different compilation strategies, etc. This is difficult when the build system is not very transparent about its fundamental data structures, or if the data structures are complex or painful to change (yes, I think Make's pattern matches are limiting).
I tried this approach with CMake: After some initial frustrations, I moved my build description to tables contained in a python script, and had that script output a CMakeLists.txt file. That removed some of the pain of working with CMake's scripting language. But custom requirements kept popping up that I found non-obvious how to implement using CMake. I soon lost motivation to deal with it.
I briefly looked around for other build systems, but as it is with many libraries and tools, I found them unapproachable and unflexible. There is a recurring scheme that the docs explain how to do X (compile a C file) or Y (add an object to a link) or Z (add a library to the search path), but not what the underlying primitives are, so that I can just do X, or W (compile a project written in my own language), myself.
I'd had this idea that a build system does not do much. It should be mostly a dependency tracker. How hard can it be to write a custom build system completely from scratch? As it turns out, the structure is not easy to get right. I needed at least three attempts. But before we come to what I think is a good approach, let's get our requirements straight:
My first attempt was by starting with two types of things: targets (e.g. compiled files) and commands (e.g. compiler invocations) as two distinct types. I would have input edges (dependencies of targets) and output edges (build outputs), each of which would connect a command and a target. I required the graph to be a DAG (sane choice), but out of necessity also that each target could be the output of at most one command.
When a command finished, I would check which of the output targets have changed, because we need to run dependent commands as well.
This model works in theory, but it's not very practical because there are too many concepts (target, command, input edge, output edge) to track and programming it gets really nasty. Also, it's not possible to chain two commands without an artificial intermediate target. I think this is another example how overzealous typing leads to bad designs.
A better approach is the following: Don't distinguish between targets and commands! Ultimately, we just need a DAG that propagates updates. We represent targets and commands uniformly as nodes, and track their dependencies as edges.
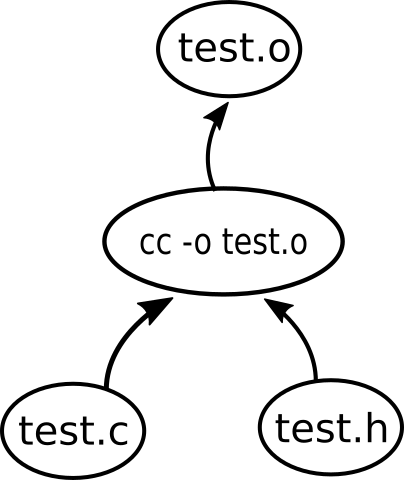
The only other concept that we introduce at this low level is triggered nodes. If a node is triggered that means that it is possibly stale -- i.e., it must be "rebuilt" as soon as possible. A node is typically triggered when one or more of its dependencies have changed.
When a node is triggered it is simply put on a to-do list. The nodes in the to-do list are processed one-by-one (respecting their dependencies -- processing only nodes that do not transitively depend on other triggered nodes). Each turn, the processed node can do its thing and report whether it did "change". If it changed, its reverse dependencies in turn are triggered as well. For example, a node representing a file on a filesystem could detect that it was really changed and the change should be propagated. When some time later one of the triggered reverse dependencies is processed -- say, a compilation command that takes the file as input -- it can examine the situation. Maybe the change to the file was not relevant (e.g. a small whitespace change). Or maybe the command decides to recompile the executable and propagate the trigger.
Whenever a node is processed, it also has the opportunity to modify its set of input dependencies. This opens up the opportunity to e.g. dynamically update header includes of a compilation whenever one of the previous dependencies was modified. Only input edges can be modified, never output edges. I don't think modifying outputs would be useful, and restricting to inputs gives us the guarantee that the build eventually finishes even when the dependencies are dynamically updated (provided that the DAG property is respected).
We do not introduce file modification times or any other means to compare nodes by their current-ness. To reduce complexity at the lowest level, we only rely on triggered nodes reporting and propagating changes. In other words, we use an edge-triggered approach, not level triggered. Level triggers can be added on top where they make sense.
This is the generic part of my prototype implementation (in python3), which I figure could be the underlying model for most build systems.
nodes = set() # set of nodes (must be hashable)
edges = set() # set of tuples (n1,n2) s.t. n1 in nodes and n2 in nodes
in_nodes = {} # node n1 -> set of nodes n2 s.t. (n2,n1) in edges
out_nodes = {} # node n1 -> set of nodes n2 s.t. (n1,n2) in edges
triggered_nodes = set() # "firing synapses"
def add_node(n):
nodes.add(n)
in_nodes[n] = set()
out_nodes[n] = set()
def remove_node(n):
nodes.remove(n)
del in_nodes[n]
del out_nodes[n]
def add_edge(n1, n2):
edges.add((n1, n2))
in_nodes[n2].add(n1)
out_nodes[n1].add(n2)
def remove_edge(n1, n2):
edges.remove((n1, n2))
in_nodes[n2].remove(n1)
out_nodes[n1].remove(n2)
def trigger_node(n):
triggered_nodes.add(n)
def calm_node(n):
triggered_nodes.remove(n)
def compute_possible_nodes():
# TODO: test for cycles
hit = set()
todo = [n for n in triggered_nodes]
while todo:
n = todo.pop()
for n2 in out_nodes[n]:
if n2 not in hit:
hit.add(n2)
todo.append(n2)
return [n for n in triggered_nodes if n not in hit]
...and that's it! We can run a little test
add_node('A')
add_node('B')
add_node('C')
add_edge('A', 'C')
add_edge('B', 'C')
trigger_node('A')
trigger_node('B')
trigger_node('C')
print(compute_possible_nodes())
In this section we make a practical build system with the help of the above DAG primitives. I'm using this system for my current software project. Note, I don't think that every build system should look like this. While some parts of it are likely to exist in most other C build systems, much of it can and will be done differently in other projects.
Before I get to the code, here is an example of the kind of build description supported by the system.
cheader lib/stb_truetype.h cheader autogen.h cheader asset.h cheader camera.h cheader data.h cheader defs.h cheader dirwatch.h cheader draw.h cheader enums.h cheader fatal.h cheader font.h cheader geometry.h cheader inputs.h cheader inputstate.h cheader logging.h cheader memory.h cheader menu.h cheader mesh.h cheader models.h cheader modules.h cheader network.h cheader opengl.h cheader platform.h cheader primgeom.h cheader projection.h cheader readfile.h cheader shaders.h cheader system-defs.h cheader tables.h cheader texture.h cheader ui.h cheader uitext.h cheader util.h cheader vertexformats.h cheader vertexobjects.h cheader window.h cheader wsl.h generate autogen [./_autogenerate.py] genIn autogen assets.wsl genIn autogen autogen.wsl genIn autogen build.wsl genIn autogen enums.wsl genIn autogen menus.wsl genIn autogen models.wsl genIn autogen modules.wsl genIn autogen shaders.wsl genIn autogen vertexobjects.wsl genOut autogen autogen.h genOut autogen autogen.c executable convert-wavefront-obj executable learn-opengl module airhockey.module module blocksgame.module module coords.module module cube.module module grid.module module meshview.module module pane.module module rotcube.module module rubik.module linkToExecutable learn-opengl asset.o linkToExecutable learn-opengl autogen.o linkToExecutable learn-opengl camera.o linkToExecutable learn-opengl data.o linkToExecutable learn-opengl dirwatch.o linkToExecutable learn-opengl draw.o linkToExecutable learn-opengl enums.o linkToExecutable learn-opengl fatal.o linkToExecutable learn-opengl font.o linkToExecutable learn-opengl geometry.o linkToExecutable learn-opengl inputs.o linkToExecutable learn-opengl inputstate.o linkToExecutable learn-opengl logging.o linkToExecutable learn-opengl main.o linkToExecutable learn-opengl memory.o linkToExecutable learn-opengl menu.o linkToExecutable learn-opengl mesh.o linkToExecutable learn-opengl models.o linkToExecutable learn-opengl modules.o linkToExecutable learn-opengl network.o linkToExecutable learn-opengl platform.o linkToExecutable learn-opengl primgeom.o linkToExecutable learn-opengl readfile.o linkToExecutable learn-opengl shaders.o linkToExecutable learn-opengl tables.o linkToExecutable learn-opengl texture.o linkToExecutable learn-opengl ui.o linkToExecutable learn-opengl uitext.o linkToExecutable learn-opengl vertexobjects.o linkToExecutable learn-opengl window.o linkToExecutable learn-opengl wsl.o linkToExecutable convert-wavefront-obj autogen.o linkToExecutable convert-wavefront-obj convert-wavefront-obj.o linkToExecutable convert-wavefront-obj fatal.o linkToExecutable convert-wavefront-obj logging.o linkToExecutable convert-wavefront-obj wsl.o linkToModule airhockey.module airhockey.o linkToModule blocksgame.module blocksgame.o linkToModule coords.module coords.o linkToModule cube.module cube.o linkToModule grid.module grid.o linkToModule meshview.module meshview.o linkToModule pane.module pane.o linkToModule rotcube.module rotcube.o linkToModule rubik.module rubik.o compile asset.c asset.o compile autogen.c autogen.o compile camera.c camera.o compile convert-wavefront-obj.c convert-wavefront-obj.o compile data.c data.o compile dirwatch.c dirwatch.o compile draw.c draw.o compile enums.c enums.o compile fatal.c fatal.o compile font.c font.o compile geometry.c geometry.o compile inputs.c inputs.o compile inputstate.c inputstate.o compile logging.c logging.o compile main.c main.o compile memory.c memory.o compile menu.c menu.o compile mesh.c mesh.o compile models.c models.o compile modules.c modules.o compile network.c network.o compile platform.c platform.o compile primgeom.c primgeom.o compile readfile.c readfile.o compile shaders.c shaders.o compile tables.c tables.o compile texture.c texture.o compile ui.c ui.o compile uitext.c uitext.o compile vertexobjects.c vertexobjects.o compile window.c window.o compile wsl.c wsl.o compilePIC airhockey.c airhockey.o compilePIC blocksgame.c blocksgame.o compilePIC coords.c coords.o compilePIC cube.c cube.o compilePIC grid.c grid.o compilePIC meshview.c meshview.o compilePIC pane.c pane.o compilePIC rotcube.c rotcube.o compilePIC rubik.c rubik.o install airhockey.module modules/airhockey.module install blocksgame.module modules/blocksgame.module install coords.module modules/coords.module install cube.module modules/cube.module install grid.module modules/grid.module install meshview.module modules/meshview.module install pane.module modules/pane.module install rotcube.module modules/rotcube.module install rubik.module modules/rubik.module
This is a relational database, written in a syntax that is more suitable than CSV. It supports more than only one table per file. Each line corresponds to a row in one of the database tables. The name of the table comes first, followed by the row's values. The database schema can be found in the python code below. (Of course we could put the data in CSV files, as well -- or in whatever format).
This particular database defines various .c, .h, and .o files, as well as executables and other data files. It also defines their relations. For example, executable learn-opengl declares an executable. An executable is created by linking a bunch of object files. These object files are listed in the linkToExecutable table. Each object file, in turn, is created by compiling a C file. The compilations are defined in the compile table.
There is another table defining compilations, namely compilePIC. It holds compilations to PIC (position independent code) objects. PIC compiled objects get linked into modules, which is what I call a shared object that implements the interface required by my plugin mechanism. There is no strong reason for making a separate table for PIC compiiled objects -- it works for me right now and prevents me from running bad linker commands. But if it bytes me later for some unforeseen reason I can change it.
Next, some utility code for interfacing with the filesystem, running build commands, and so on. Not small or neat code, but neither a maintenance burden.
"""
A little filesystem interfacing and process launching first
"""
import os
import subprocess
import sys
def file_mtime(fpath):
try:
mtime = os.path.getmtime(fpath)
assert mtime is not None
except FileNotFoundError:
return None
return mtime
def write_file(fpath, contents):
f = open(fpath, 'w')
f.write(contents)
f.close()
def run_proc(*args):
print('RUN:', *args)
r = subprocess.run(args)
ecode = r.returncode
if ecode != 0:
print('ERROR: exitcode', ecode, 'from', *args)
sys.exit(1)
def read_proc(*args):
print('RUN:', *args)
r = subprocess.run(args, stdout=subprocess.PIPE)
ecode = r.returncode
if ecode != 0:
print('ERROR: exitcode', ecode, 'from', *args)
sys.exit(1)
return r.stdout
def compile_c_file(src, dst, opts):
run_proc("cc", "-c", "-g", "-Wall", "-O0", *opts, "-o", dst, src)
def compute_c_deps(src, opts):
out = read_proc("cc", "-MM", "-MG", *opts, src)
toks = out.decode().split()
assert len(toks) >= 1
assert toks[0].endswith('.o:')
return [tok for tok in toks[1:] if tok != '\\']
def link_object_file(dst, objects, opts):
Gopts = ["-ldl", "-lm", "-lGL", "-lGLU", "-lGLEW", "-lglfw"]
run_proc("cc", "-g", "-o", dst, *Gopts, *opts, *objects)
def shellcmd(cmd):
run_proc("sh", "-c", cmd)
def copy_file(src, dst):
# cp doesn't copy by renaming. Therefore replacing an existing file is not
# atomic. That's inconvenient when replacing a plugin or another
# hot-reloaded file. Strategy: copy to temporary file and then use mv.
tmp = dst + '.new'
if os.path.exists(tmp):
raise Exception("Can't update file {} since temporary file {} exists"
.format(dst, tmp))
run_proc('sh', '-c', 'cp --no-clobber -T "$1" "$2" && mv -T "$2" "$3"',
'--', src, tmp, dst)
def later(func, *args, **kwargs):
"""Bind arguments earlier than a plain lambda would (which causes problems
in loops) """
return lambda: func(*args, **kwargs)
Finally, here comes the code which takes above build description, converts it into a dependency graph, reads the state cache from another file, builds all non-current targets, and writes back the updated state to the cache. The code itself is not too pretty, and does not fit every purpose perfectly, but that's not the point. Or rather, that's exactly the point: the code is reliable, deletable, editable and adaptable. That's what I want from a build system!
"""
Let's get to the meat
"""
sys.path.insert(0, 'python-wsl')
import wsl
node_impl = {} # node-id => Node object (FileNode and CmdNode below)
file_nodes = set() # subset of those nodes that are FileNode nodes
file_tstamp = {} # file system filepath => last known modification time
scan_of_oPath = {} # .o path => node-id of command used for deps scanning
compile_of_oPath = {} # .o path => node-id of command used for compilation
cPath_of_oPath = {} # .o path => .c path used to compile .o
sourcedep = {} # .o path => .c path and all included files
execorder = {} # registered node => execution order (default 0)
"""
Two kinds of nodes in our dependency graph: FileNode represents a file in the
filesystem. CmdNode represents an abstract computation.
Both have an update method that returns whether the node's reverse dependencies
should be triggered.
"""
class FileNode:
def __init__(self, fpath):
self.fpath = fpath
def update(self):
tstamp = file_mtime(self.fpath)
r = tstamp is None or file_tstamp[self.fpath] != tstamp
file_tstamp[self.fpath] = tstamp
return r
def __repr__(self):
return 'File(%s)' %(self.fpath)
class CmdNode:
def __init__(self, cmdId, desc, proc):
self.cmdId = cmdId
self.desc = desc
self.proc = proc
def update(self):
self.proc()
return True
def __repr__(self):
return 'Cmd(%s)' %(self.cmdId)
"""
Higher level graph manipulation, suitable for the things we want to build
"""
def add_file_node(fpath):
# the conditional is a little dirty. We might want to move it even more to
# the outside
if fpath not in nodes:
add_node(fpath)
node_impl[fpath] = FileNode(fpath)
file_nodes.add(fpath)
file_tstamp[fpath] = None
def add_cmd_node(cmdId, desc, proc):
assert cmdId not in nodes
add_node(cmdId)
node_impl[cmdId] = CmdNode(cmdId, desc, proc)
def add_cmd_and_file_nodes(fpath, cmdId, desc, proc):
assert fpath not in nodes
add_cmd_node(cmdId, desc, proc)
add_file_node(fpath)
add_edge(cmdId, fpath)
def add_sourcedep(chPath, oPath):
assert chPath in nodes
sourcedep[oPath].add(chPath)
add_edge(chPath, scan_of_oPath[oPath])
def clear_sourcedeps(oPath):
for chPath in sourcedep[oPath]:
remove_edge(chPath, scan_of_oPath[oPath])
sourcedep[oPath].clear()
def update_compile_deps(cPath, oPath, opts):
clear_sourcedeps(oPath)
deps = compute_c_deps(cPath, opts)
for chPath in deps:
if chPath not in nodes:
print('ERROR: %s (transitively) includes unregistered file %s. You '
'might want to register it with a "cheader %s" line in '
'build.wsl' %(cPath, chPath, chPath))
sys.exit(1)
add_sourcedep(chPath, oPath)
def add_compile_command(cPath, oPath, opts):
scanCmd = 'scanincludes-%s' %(oPath)
scanDesc = 'Scan includes for compilation %s => %s' %(cPath, oPath)
scanProc = later(update_compile_deps, cPath, oPath, opts)
compileCmd = 'compile-%s' %(oPath)
compileDesc = 'Compile C file %s => %s' %(cPath, oPath)
compileProc = later(compile_c_file, cPath, oPath, opts)
add_cmd_node(scanCmd, scanDesc, scanProc)
add_cmd_node(compileCmd, compileDesc, compileProc)
add_file_node(oPath)
add_edge(scanCmd, compileCmd)
add_edge(compileCmd, oPath)
scan_of_oPath[oPath] = scanCmd
compile_of_oPath[oPath] = compileCmd
cPath_of_oPath[oPath] = cPath
sourcedep[oPath] = set()
execorder[scanCmd] = -1
def node_sort_key(node):
return execorder.get(node, 0)
"""
Read cache file using WSL library
"""
cacheschema = wsl.parse_schema("""
DOMAIN ID ID
DOMAIN Float Float
TABLE Timestamp ID Float
TABLE CompileC ID
TABLE SourceDep ID ID
KEY k0 Timestamp f *
KEY k1 CompileC o
REFERENCE r0 SourceDep o * => CompileC o
""")
if os.path.exists('build.cache'):
_, cachetables = wsl.parse_db(dbfilepath='build.cache', schema=cacheschema)
else:
_, cachetables = wsl.parse_db(dbstr='', schema=cacheschema)
cached_sourcedep = {}
cached_tstamps = {}
for oPath, in cachetables['CompileC']:
cached_sourcedep[oPath] = set()
for oPath, chPath in cachetables['SourceDep']:
cached_sourcedep[oPath].add(chPath)
for fpath, tstamp in cachetables['Timestamp']:
cached_tstamps[fpath] = tstamp
"""
Read tabular build description with WSL library
"""
wslschema = wsl.parse_schema("""
DOMAIN GenID ID
DOMAIN File ID
DOMAIN Command String
TABLE cheader File
TABLE compile File File
TABLE compilePIC File File
TABLE generate GenID Command
TABLE genIn GenID File
TABLE genOut GenID File
TABLE depends File File
TABLE executable File
TABLE module File
TABLE linkToExecutable File File
TABLE linkToModule File File
TABLE install File File
KEY k0 generate g
KEY k1 executable e
KEY k2 compile * o
KEY k3 module m
KEY k4 compilePIC * o
REFERENCE r0 genIn g * => generate g *
REFERENCE r1 genOut g * => generate g *
REFERENCE r2 linkToExecutable e * => executable e
REFERENCE r3 linkToExecutable * o => compile * o
REFERENCE r4 linkToModule m * => module m
REFERENCE r5 linkToModule * o => compilePIC * o
""")
_, wsltables = wsl.parse_db(dbfilepath='build.wsl', schema=wslschema)
wsl.check_database_integrity(wslschema, wsltables)
"""
Transform tabular build description into build dependency graph
"""
for (chPath,) in wsltables['cheader']:
add_file_node(chPath)
for cPath, oPath in wsltables['compile']:
add_file_node(cPath)
add_compile_command(cPath, oPath, [])
for cPath, oPath in wsltables['compilePIC']:
add_file_node(cPath)
add_compile_command(cPath, oPath, ['-fPIC'])
for fpath, in wsltables['executable']:
oPaths = []
for fpath2, oPath in wsltables['linkToExecutable']:
if fpath2 == fpath:
oPaths.append(oPath)
cmdId = 'link-%s' %(fpath)
desc = 'Make module %s' %(fpath)
proc = later(link_object_file, fpath, oPaths, ['-Wl,--export-dynamic'])
add_cmd_and_file_nodes(fpath, cmdId, desc, proc)
for oPath in oPaths:
add_edge(oPath, cmdId)
execorder[cmdId] = 0
for fpath, in wsltables['module']:
oPaths = []
for fpath2, oPath in wsltables['linkToModule']:
if fpath2 == fpath:
oPaths.append(oPath)
cmdId = 'link-%s' %(fpath)
desc = 'Make module %s' %(fpath)
proc = later(link_object_file, fpath, oPaths, ['-shared'])
add_cmd_and_file_nodes(fpath, cmdId, desc, proc)
for oPath in oPaths:
add_edge(oPath, cmdId)
execorder[cmdId] = 1
for genId, cmd in wsltables['generate']:
cmdId = genId
desc = 'Generate "%s"' %(genId)
proc = later(shellcmd, cmd)
add_cmd_node(genId, desc, proc)
execorder[genId] = -2
for genId, fpath in wsltables['genIn']:
add_file_node(fpath)
add_edge(fpath, genId)
for genId, fpath in wsltables['genOut']:
add_file_node(fpath)
add_edge(genId, fpath)
for src, dst in wsltables['install']:
cmdId = 'install-%s' %(dst)
desc = 'Install %s => %s' %(src, dst)
proc = later(copy_file, src, dst)
add_cmd_and_file_nodes(dst, cmdId, desc, proc)
add_edge(src, cmdId)
execorder[cmdId] = 2
"""
Compare cached state to current state and trigger if necessary
"""
for fpath in file_nodes:
file_tstamp[fpath] = cached_tstamps.get(fpath, None)
for fpath in file_nodes:
tstamp = file_mtime(fpath)
if file_tstamp[fpath] != tstamp:
trigger_node(fpath)
# hack, for now
if fpath in sourcedep:
trigger_node(compile_of_oPath[fpath])
for oPath in sourcedep:
cPath = cPath_of_oPath[oPath]
stale = False
if oPath not in cached_sourcedep:
stale = True
elif cPath not in cached_sourcedep[oPath]:
stale = True
else:
for chPath in sorted(cached_sourcedep[oPath]):
if chPath not in nodes:
stale = True
break
if stale:
trigger_node(scan_of_oPath[oPath])
continue
for chPath in cached_sourcedep[oPath]:
add_sourcedep(chPath, oPath)
"""
Execute necessary actions
"""
while triggered_nodes:
possible = compute_possible_nodes()
assert len(possible) > 0
# Choose one of the possible nodes of lowest sort rank
n = sorted(possible, key=node_sort_key)[0]
changed = node_impl[n].update()
if changed:
for n2 in out_nodes[n]:
trigger_node(n2)
calm_node(n)
"""
Write cache file using WSL library
"""
tbl_Timestamp = []
tbl_CompileC = []
tbl_SourceDep = []
for fpath, tstamp in file_tstamp.items():
tbl_Timestamp.append((fpath, -1.0 if tstamp is None else tstamp))
for oPath in compile_of_oPath.keys():
tbl_CompileC.append((oPath,))
for oPath, cPaths in sourcedep.items():
for cPath in cPaths:
tbl_SourceDep.append((oPath, cPath))
cachetables = {
'Timestamp': tbl_Timestamp,
'CompileC': tbl_CompileC,
'SourceDep': tbl_SourceDep,
}
dbstring = wsl.format_db(cacheschema, cachetables, inline_schema=False)
write_file('build.cache', dbstring)
If you want to play with the code, you need also my library python-wsl, for reading and writing the build description. But I encourage you to write your own variant.
Created: 2018-02-25. Last updated: 2018-03-08